

Mirror, mirror on my data lake

If you’ve been reading about the new Sentinel data lake, you’ve undoubtedly seen that data from analytics logs is “mirrored” to the data lake. But what does that actually mean?
What is data mirroring?
In the context of the Sentinel data lake, data mirroring refers to the automatic duplication of data from the analytics tier into the data lake tier. This process guarantees that all newly ingested data is available in both tiers without you having to provide some kind of manual intervention or do any additional configuration.
Once a workspace is onboarded to the Sentinel data lake, all analytics tier data is mirrored into the data lake tier from that point forward.
Mirroring is automatic and cost-neutral, there are no additional charges for mirrored data if the “Total retention” retention period matches the “Analytic tier” retention period.
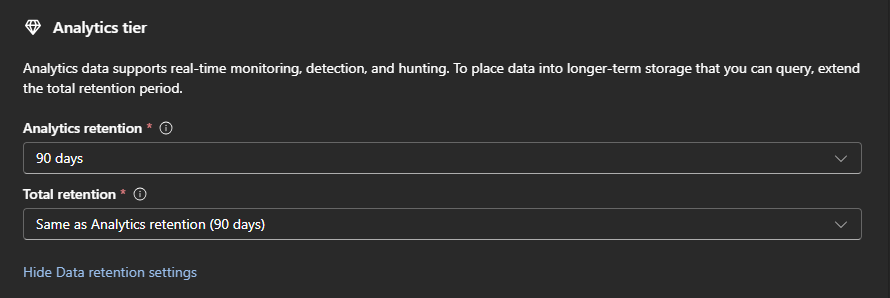
Just a note, data that was already in your analytics tier is not retroactively mirrored into the data lake. Only new data is mirrored.
What does data mirroring do for me?
Data mirroring provides several benefits. It delivers:
The ability to query both short-term and long-term data at the same time whether you are doing forensic investigations or simply searching for interesting patterns.
Flexible querying using KQL or Spark-based notebooks.
Seamless integration with existing Sentinel connectors. You don’t need to change any of your existing data collection methods.
Cost optimization, especially for high volume, low-fidelity logs (think firewall or sysmon) that benefit from lake-only retention. Many environments don’t ingest these kinds of logs because they are too expensive. But with the data lake pricing this will hopefully be improved.
A few caveats
While data mirroring will be a huge boon, there are a few things to be aware of.
By default, XDR data is automatically retained for 30 days and is accessible via advanced hunting. If you do not go into the Tables blade and change the retention, the XDR data is not ingested into Log Analytics so it cannot be mirrored to the data lake.
There is no way to mirror XDR data to the lake out of the box without first storing it in Log Analytics. Jeffrey Appel published a great post How to store Defender XDR data for years in Sentinel data lake without expensive ingestion cost.
Custom tables created using the Azure Monitor Log Ingestion API are supported for data lake mirroring. But custom tables created using the now deprecated HTTP Data Collector API (includes tables created using the legacy MMA) are not supported for data lake mirroring.
Hope that helps clear things up!